Home
About
Archive
Categories
Pages
Tags
Continuously Deployed
Continuously Deployed
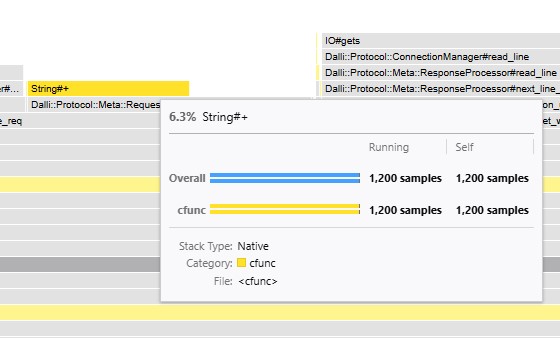
Ruby Caches - Improving Caching Via Tooling
10 February 2025
Ruby
Ruby Caches - Rails Local Cache Strategy
17 December 2024
Ruby
Ruby Caches - Rails Cache Network Requests
07 November 2024
Ruby
Ruby Caches - Rails Cache Workflows
24 October 2024
Ruby
Creating Consistent Characters Across Images
22 October 2024
Programming
Ruby Caches - Rails Cache Comparisons
20 October 2024
Ruby
Ruby Caches - Rails Cache Initialization
17 October 2024
Ruby