
Phone Number DB Types
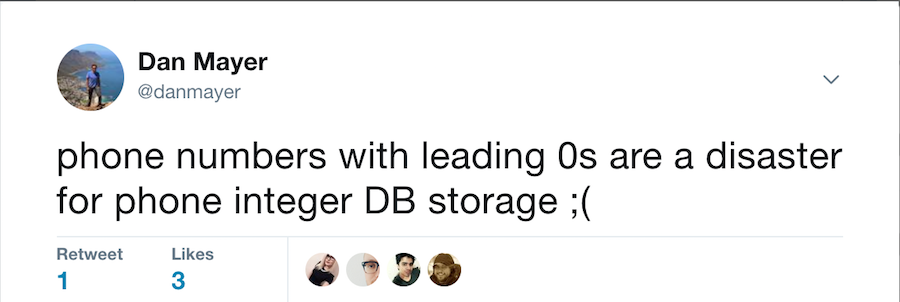
tweeting about DB phone number formats
How to best store & query phone numbers in Postgres DB
Update: 06-27-2017, See the update & round 2 section below for improved and corrected data
After some frustration cleaning up some of our information architecture related to phone numbers. I posted the tweet at the top of this article.
It actually lead to far more responses, questions, and discussion about the best way to store numbers… It made me think that perhaps our quick attempts to extract the best process out of multiple production table cleanups, could be missing something. I decided it would be pretty easy to try to dig in a bit deeper for a more data backed answer. I definitely don’t claim to be a DB performance expert, so perhaps we had reached some wrong conclusions.
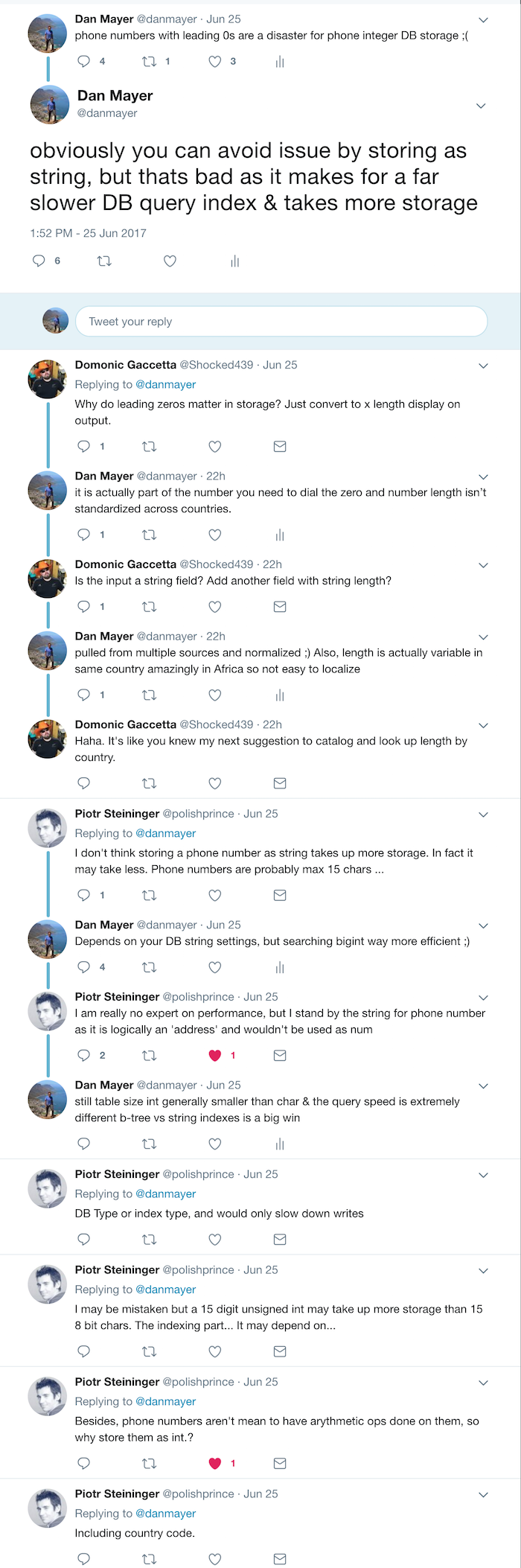
a portion of the sub-discussion from the original tweet
a pretty strong statement saying we got this wrong
Open Questions
The premise we ended up with was that it was worth a tradeoff of some complexity to store phone numbers as bigint vs varchar in our Postgres DB.
Everyone admits it is easier to work with a string number and it avoids the leading 0 problem. Is there a valid reason to use bigint vs varchar?
The thread brought up a few open questions:
- What is the difference in DB table storage size?
- What is the performance difference
- the difference on insertion time?
- the difference on query time?
OK, we should be able to answer these fairly easily.
Benchmark Setup
Create Simple Tables with our unique index
class DemoTables < ActiveRecord::Migration[5.1]
def change
create_table :demo_int_phone_numbers do |t|
t.bigint :phone_number, limit: 8, null: false
end
add_index :demo_int_phone_numbers, [:phone_number], unique: true
create_table :demo_string_phone_numbers do |t|
t.string :phone_number, limit: 8, null: false
end
add_index :demo_string_phone_numbers, [:phone_number], unique: true
end
end
Create our simple AR models
class DemoIntPhoneNumber < ActiveRecord::Base
end
class DemoStringPhoneNumber < ActiveRecord::Base
end
Build a simple benchmark script
namespace :demo do
task :perf => :environment do
DemoStringPhoneNumber.destroy_all
DemoIntPhoneNumber.destroy_all
GC.start
puts "benchmarking insertions"
Benchmark.bm(7) do |bm|
bm.report do
(0...200_000).each do |val|
DemoStringPhoneNumber.create!(phone_number: val)
end
end
end
GC.start
Benchmark.bm(7) do |bm|
bm.report do
(0...200_000).each do |val|
DemoIntPhoneNumber.create!(phone_number: val)
end
end
end
GC.start
puts "benchmarking queries"
Benchmark.bm(7) do |bm|
bm.report do
(0...200_000).each do |val|
DemoStringPhoneNumber.where(phone_number: val).first
end
end
end
GC.start
Benchmark.bm(7) do |bm|
bm.report do
(0...1200_000).each do |val|
DemoIntPhoneNumber.where(phone_number: val).first
end
end
end
end
end
Table Size Results
I was wrong on table size… Looking back as we moved phone numbers from many tables to a single phone_numbers table a number of them were using different types, including varchar, which did make the tables bigger… but that was because a number of the old tables hadn’t set a limit meaning it defaulted to varchar(255). Once you set a limit bigint and string with limit: 8 will result in the same size of table.
select pg_size_pretty(pg_relation_size('demo_int_phone_numbers'));
=> 8656 kB
select pg_size_pretty(pg_relation_size('demo_string_phone_numbers'));
=> 8656 kB
Insertion Performance Results
I actually didn’t expect a difference on this but someone mentioned there could be a slower insertion time… It looks like nothing noticeable on insertion which is nice.
# benchmarking insertions
user system total real
385.130000 35.700000 420.830000 (568.695180)
user system total real
371.370000 34.110000 405.480000 (543.861259)
Query Performance Results
While numerous performance blog posts say that a Postgres btree index is more performant for integers than strings. Sample data doesn’t show as big of a difference as I was expecting. The performance benefit is questionable. It is there, but doesn’t seem worth the effort. Since this is a quick and dirty benchmark one would have to be more systematic to prove out a real difference. I think my simplification of just having sequential numbers inserted could not realistically simulate how a production index ends up.
# 200,000 queries against String Table
user system total real
194.320000 15.400000 209.720000 (265.271056)
# 200,000 queries against Int Table
user system total real
160.390000 13.010000 173.400000 (210.774260)
In that end this does show a small difference, but nothing to be impressed about.
Bad Assumptions
From our cleanup of multiple tables we had multiple issues and conditions which lead me to conflate some of the issues.
- Our DB had a number of columns that were
varchar(255)opposed to using a correct limit. This entirely counts for the table size difference. - I am curious if having unused space in a
varcharfield can still impact query performance, I am not sure about this. - We weren’t enforcing a unique index, instead sometimes relying on Rails
validates :field_name uniqueness: true, and sometimes not even enforcing uniqueness. Which I think could impact query time more significantly when there are duplicates. Proving this out would require more benchmarking.
Conclusions
Let’s revisit our questions:
Is there a valid reason to use
bigintvsvarchar?
Not really, there may be slight query performance wins, but far less than I thought.
What is the difference in DB table storage size?
None, I was wrong
What is the performance difference on insertion time?
None, which I expected but some other folks expected to see.
What is the performance difference on query time?
Slight difference, more detailed benchmarking would be good… Initial results show this to be far less significant than initially thought. I will say this one is dependent on the performance characteristics you see in production. That being said my assumptions here were still a bit flawed, and I was surprised by the results.
Update: Limit Not What You Think…
OK so this post made sense to folks, but then people were asking why I am limiting the phone number to 8, which wouldn’t work in various countries… in fact it wouldn’t work for our countries either… I will need to rerun my benchmarks and I believe get different results.
We have historically put limit in our int fields when doing something other than the default. The limit has a different meaning for numerical and string types for Rails DB migrations.
The :limit on bigint or int in Rails refers to the byte size not a length limit. bigint limit: 8 is redundant as 8 bytes is the max. Prior to Rails supporting the bigint type, the way to get a bigint was to actually use int limit: 8. In fact if you look at the schema after creating a bigint limit: 6 the limit is just ignored by postgres (and by mysql it seems). The DB storage type ends up as a bigint with 8 bytes of storage. This post explains the oddness of int limits well.
Limit on string dos what you expect and limits the length of the string. The way I was generating phone numbers never tested this as I simply generated between (0...200_000).
# storing a typical TZ number for us
DemoIntPhoneNumber.create!(phone_number: 2551234567890)
# storing an actual max, which is far larger than we need
DemoIntPhoneNumber.create!(phone_number: 9223372036854775807)
# lets try those with our string limit version
DemoStringPhoneNumber.create!(phone_number: 2550677939180)
ActiveRecord::ValueTooLong: PG::StringDataRightTruncation: ERROR: value too long for type character varying(8)
# and clearly the max won't work at all...
My benchmark isn’t valid as varchar(8) isn’t really the same as bigint. The fact that tables size was previously the same was a bad coincidence, which I think shows that bigint is actually more efficient.
Let’s try again, varchar actually needs to hold 13 for our max length number, and 15 for German numbers. So we will compare bigint to varchar(15), even though bigint can technically hold numbers of length 19.
Benchmarking Round 2
Setup Changes
Let’s create two new tables the first verifies with the type bigint that the limit option is ignored it just creates a table with an 8 byte bigint Postgres type. The second creates a new string table with a varchar(15)
class DemoTablesTwo < ActiveRecord::Migration[5.1]
def change
create_table :demo_smallint_phone_numbers do |t|
t.bigint :phone_number, limit: 6, null: false
end
add_index :demo_smallint_phone_numbers, [:phone_number], unique: true
create_table :demo_bigstring_phone_numbers do |t|
t.string :phone_number, limit: 15, null: false
end
add_index :demo_bigstring_phone_numbers, [:phone_number], unique: true
end
end
OK then we will need a quick AR class
class DemoBigstringPhoneNumber < ActiveRecord::Base
end
Then the benchmark improvements
namespace :demo do
task :perf => :environment do
DemoBigstringPhoneNumber.delete_all
DemoIntPhoneNumber.delete_all
base_number = 2550000000000
max_number = (base_number + 150_000)
GC.start
puts "benchmarking insertions"
Benchmark.bm(7) do |bm|
bm.report do
(base_number...max_number).each do |val|
DemoBigstringPhoneNumber.create!(phone_number: val)
end
end
end
GC.start
Benchmark.bm(7) do |bm|
bm.report do
(base_number...max_number).each do |val|
DemoIntPhoneNumber.create!(phone_number: val)
end
end
end
# lets not just have sequential numbers lets get some better data by inserting arbitrary numbers
(75_000).times do
val = max_number + rand(90_000_000)
begin
DemoBigstringPhoneNumber.create!(phone_number: val)
DemoIntPhoneNumber.create!(phone_number: val)
rescue => err
# ignore duplicates that occur because of rand
puts err
end
end
GC.start
puts "benchmarking queries"
Benchmark.bm(7) do |bm|
bm.report do
DemoBigstringPhoneNumber.find_each do |val|
DemoBigstringPhoneNumber.where(phone_number: val.phone_number).first
end
end
end
GC.start
Benchmark.bm(7) do |bm|
bm.report do
DemoIntPhoneNumber.find_each do |val|
DemoIntPhoneNumber.where(phone_number: val.phone_number).first
end
end
end
end
end
Table Size Results
After running a number of tests, the tables size issue does become more clear. This now matches my original expectation.
select count(*) from demo_int_phone_numbers; => 339669
select pg_size_pretty(pg_relation_size('demo_int_phone_numbers'));
=> 14 MB
select count(*) from demo_bigstring_phone_numbers; => 339669
select pg_size_pretty(pg_relation_size('demo_bigstring_phone_numbers'));
=> 17 MB
Insertion Performance Results
Again no real difference.
Query Performance Results
Results are are starting to show a bit more more of a difference. Likely, more valid as this time we aren’t just querying sequential numbers but we have some randomness introduced.
# queries against String Table varchar(15)
user system total real
377.940000 28.550000 406.490000 (550.554212)
# queries against Int Table
user system total real
302.260000 23.320000 325.580000 (403.738332)
Revisited Conclusions
Let’s revisit our questions:
Is there a valid reason to use
bigintvsvarchar?
Perhaps, the query improvements are smaller than I thought, but noticeable. The table size difference is real, but also not that large. It would really depend on your needs and the size of your tables. In the end Google says never store phone numbers as numeric data (rule #24), but given a known set of countries and query performance, you can examine the tradeoffs.
What is the difference in DB table storage size?
Yes, there is a difference. The type bigint is a more efficient way to store 15 digit numbers.
What is the performance difference on insertion time?
None, which I expected but some other folks expected to see.
What is the performance difference on query time?
The larger set of test data and introducing randomness into the data seems to show an increasing improvement for bigint queries. While it is still small than I anticipated, it does seem to have a real impact.