
Performance of JSON Parsers at Scale

photo credit qimono@pixabay
Performance of JSON Parsers at Scale
In a recent post, benchmarking JSON Parsers (OJ, SimdJson, FastJsonParser). This compared the parsers based on local microbenchmarks. In the end, I recommended for almost all general use cases go with OJ. Saying that FastJsonParser might be worth it for specific use cases. I want to do a quick follow up on sharing what happens when microbenchmarks meet real-world data, scale, and systems.
TL; DR; you probably just want to use OJ as originally recommended, even on data where FastJsonParser wins in a microbenchmark, the real-world data was undetectable. While moving from StdLib to OJ was a 40% latency improvement holding up across multiple services.
Microbenchmarks
As often the case microbenchmarks come with a lot of issues. In this case, my microbenchmarks showed with a single example of real-world data that FastJsonParser was that faster and had the lowest memory usage… OJ was about 1.55x slower in both with_keys and normal string key benchmarks. I benchmarked against two JSON pieces, a very small fake JSON payload, and a real-world large payload pulled from one of our production systems. For the specific examples, I used and with no other concerns yes FastJsonParser is faster, but that doesn’t mean it will translate into a real-world performance win.
Given that we had previously seen 40% latency improvements when moving to OJ, it seemed like another 50% speed lift would be worth it, so I set out to test FastJsonParser on some of our production systems.
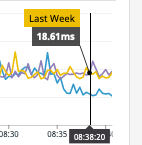
Last week / Yesterday -> OJ released with 40% latency improvement
What Does Real World & At Scale Mean?
In my case, I started with a single app having all API calls use FastJsonParser to parse responses as well as when pulling JSON out of caches. The single app had a smaller JSON payload than I benchmarked with but had a very high throughput. After deployment, there was no detectable change in latency… Why not?
- At that point, the way the app was performing was already fairly well optimized
- According to DataDog trace spans JSON parsing was taking up less than 1ms of response time
- Um… what is 50% faster on 1ms of a response, where JSON parse wasn’t even in the top 10 time-consuming spans of building the response? Nothing really
OK, I figured I picked a bad test case… I had originally benchmarked with a large JSON collection blob that passed through multiple systems. I decided to target 5 applications that worked together that used and served the original data I used to benchmark. This broke down like so:
- 1 front end app
- 4 microservices sending different JSON payloads
In total that large JSON collection data was passed through 3 of the 5 apps, with other JSON data coming from the other services. I figured this would have a bunch of small wins that would add up to show reduced latency for the front end application. Since all the small gains would eventually roll up to its final response time.
After sending out 5 PRs, getting approvals, deploying, I played a waiting game watching graphs and collecting data… NOTHING, I could see nothing. No errors, no problems, no performance impact.
Why Wasn’t It Faster?
I think similar to the single app example, even in this case OJ had really already captured the majority of the wins. JSON.parse was no longer in the top 10 spans of any of the 5 apps I updated. It previously was a part of the critical performance path… It no longer was… I am guessing there might have been tiny improvements, but nothing I could see with the naked eye… For most of these services, a 1ms improvement in each service, wouldn’t have been visible with all the random network noise.
I think just network latency outweighed any further improvement on JSON parsing… None of the payloads were large or complex enough to drive a significant cost. This goes back to the original point, you need to really have a good reason to spend the extra time with FastJsonParser to drive further improvements over OJ’s Json.parse drop-in replacement which also ensures all the Rails toolchain and middleware is using the improvements. Since FasterJsonParser requires the developer to explicitly call FastJsonparser.parse I only did that where we handled API calls, it took more work and it wasn’t an improvement. If you have spans where JSON.parse is showing significant time in your application traces, it could be different for you.
Microbenchmark -> Welcome to the real world
Conclusion
Unless you are maintaining a gem and are avoiding dependencies, I highly recommend using OJ for your applications. It requires very low effort and holds up in microbenchmarks and across many different services and real-world data.