Production Code Analysis
I am here to talk about production code analysis, Tales of Deleting 200K+ LOC.
As the talk title indicates I am focusing on finding unused code using analysis.
Spaghetti Code
 -
overload studios
-
overload studios
|
 -
troll.me
-
troll.me
|
We have all seen spaghetti code. It is hard to understand
Hard to follow all the code paths.
It is difficult to change and maintain.
As projects grow and age it is very difficult to entirely avoid.
Untangling it is hard but runtime analysis can help.
First I want to briefly explain how a project can reach a point where there is over 200KLOC that can be removed.
Then I can explain some processes to help find and remove unnecessary complexity in your apps.
MonoRail The Simpsons
-
Pre Existing
 Yes, we have a MonoRail app. A monolithic multiple years old Rails app with legacy code...
Yes, we have a MonoRail app. A monolithic multiple years old Rails app with legacy code...
Actually we have more than one, how did we get here. A bit of history.
The application began as a fork of an existing project to quickly validate an idea. -
Consumer
 That grew into a consumer business, which is what most people know as LivingSocial today.
That grew into a consumer business, which is what most people know as LivingSocial today.
That app grew a lot and had many teams working to extend its functionality.
Eventually it was forked into multiple other applications. -
Admin

CMS

CRMS
 This means all these apps share some of the same code, but after each split they have less responsibility.
This means all these apps share some of the same code, but after each split they have less responsibility.
Which code is needed for the smaller slice of responsibilities, what can be removed from the parent or child app?
No Cleanup...

You will eventually crash.
Looking at what the actual code is doing can help can help tell you what is necessary.
While the forking of one MonoRail into two might be uniq to our situation, dead code in large apps is not.
(images are from one of my favroite episodes of the Simpsons)
How Dead Code Sticks Around
- Large teams aren't good at communicating what is no longer needed (both Biz & Dev)
- A/B tests, never removing a loser
- One offs that are irrelevant over time
- Deprecation of old endpoints takes time
- Refactoring leaves dead code paths behind
- Making a 'safe' change & creating new methods opposed to altering existing methods with multiple callers
- There are tests, but it is never used in production
- etc...
I am not really going into all the details, but suffice to say. Every system I have worked on grows and at some point has unnecessary code tucked away into dark corners.
Features that don't quite justify their UI complexity,
pivoting away from some direction,
either for business or development reasons,
AB tests, the list goes on and on.
I am sure many of you have seen this in your own apps.
All code is bad
Also, the bridge was designed as a suspension bridge, but nobody actually knew how to build a suspension bridge, so they got halfway through it and then just added extra support columns to keep the thing standing
In it he makes the analogy of a team building a bridge, not knowing what they are doing.
resulting in them building half a suspension and half a support bridge.
Several things in this article jumped out at me.
such as the statement, "all code is bad".
Which obviously not entirely true, must mean...
Less Code Is Better
- is easier to reason about
- is easier to upgrade (Rails, Ruby, and Gem versions)
- is easier to refactor
- is easier to adapt to new requirements
- means there are fewer and faster tests
Obviously if code is doing work for your business it has some value, but I don't think I have to spend much time time explaining why having less code & simpler systems is better.
Less Code for many reasons makes it easier you and your team to focus on making important changes.
Solution: Clean Up Dead Code
- If "All Code is Bad"
- Less Code is Better
- Keep Only the Code Needed, No More
clean up unused code.
Keeping only the code needed.
We can make our projects better by only working on what is providing value.
Code that is actively in use by our business and users.
Sounds good, let's delete all the code...
Or some of it, which code...
All code is bad
They left the suspension cables because they're still sort of holding up parts of the bridge. Nobody knows which parts, but everybody's pretty sure they're important parts.
something else struck me...
"They left the suspension cables because they're still sort of holding up parts of the bridge."
and now for the line that really stood out
How to know: Production Code Analysis
Nobody knows which parts, but everybody's pretty sure they're important parts.
Hmmm Really? Nobody knows which parts?
We don't have to settle for guessing, we can solve this problem...
We can use data.
We can use code and analytics.
Analyzing Production Code
- Use NewRelic, skylight.io, or Appneta Traceview (formerly Tracelytics)
- Custom Stats Instrumentation
- Use Logs
- Production Code Coverage
I am going to go through some examples of processes we have used to find unused code. From very simple methods, to more complicated processes.
We will talk about 3rd party tools
Cumstom Stats
Using Logs
and Prodcution Code Coverage
Also, note if you run `rake stats` on a Rail app and have less than 3-5K lines of code.
You can probably just reason about the code in your head.
and these tools might seem like overkill.
We had apps pushing 80K lines of app code
excluding the view layer, javascript, and CSS.
Street Cred
(grown up marketing speak: "street cred" => "social proof")
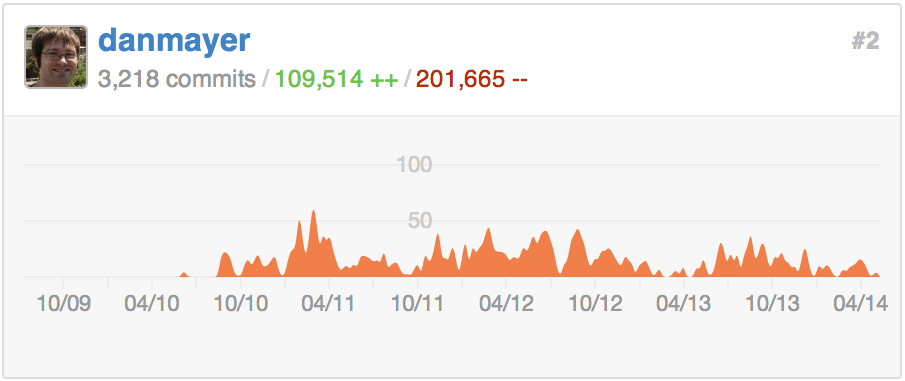
Here is my history on one of our Monorails apps.
I am pretty proud to have removed nearly 2 lines of code for every one added, while delivery additional functionality and faster performance.
Team Effort
My diff over last 2 years
+20973, -47034
Team diff over last 2 years
+197326, -215514
You can see my contributions over the last 2 years are dwarfed by the teams efforts
As a team we celebrate our code improvements.
Pointing out and cheering on particularly good commits, faster tests, code deletion.
Linking to little victories in campfire all the way.
Git Spelunking
[~/projects/deals]git log --numstat --pretty="%H" --author="dan.mayer" --since="2 years ago" app | awk 'NF==3 {plus+=$1; minus+=$2} END {printf("+%d, -%d\n", plus, minus)}'
[~/projects/deals] git log --numstat --pretty="%H" --since="2 years ago" app | awk 'NF==3 {plus+=$1; minus+=$2} END {printf("+%d, -%d\n", plus, minus)}'
Problem: Unused Actions
Let's start by finding actions and routes that are out of use.
This is one of the easiest ways to find unnecessary code.
It also can be the most rewarding by removing the top level action
then following through to remove associated helpers, views, and occasionally models.
Using 3rd Party tool (NewRelic)
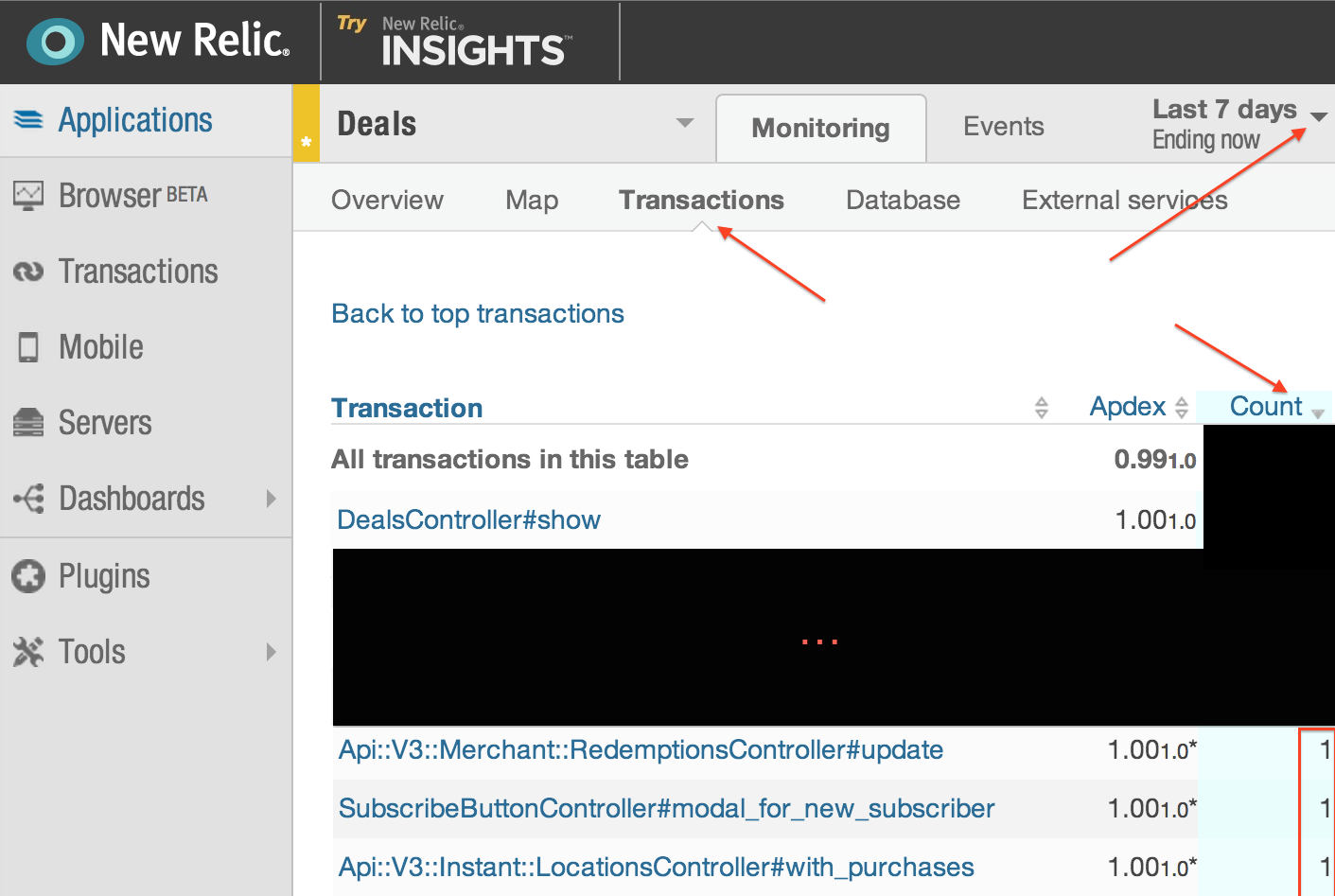
Easiest way, look transactions over last 7 days: (note won't help with specific formats or never hit endpoints)
There are a number of popular Ruby performance monitoring services. Each allow you to hook into their service sending some data to help you monitor and find performance issues.
In this case NewRelic but Skylight.io & Traceview can get you the same data.
In the NewRelic transaction view you can sort transactions broken down by controller route by usage.
Anything with 1 view in the last seven days likely isn't pulling its weight. It might be worth discussing the cost of those features with the team.
Some of them you may be able to cut.
A problem with this view, is that it doesn't show which actions received 0 requests.
Using 3rd Party tool (NewRelic)
LS made a gem to help, newrelic_route_check compare NR reports to Rails routes. download the `controller_summary.csv`

run `bundle exec rake newrelic:compare_with_routes`
found 335 uniq new relic controller action hits found 562 uniq Rails routes controller action pairs exists in new relic, but not in routes: 0 never accessed in new relic stats: *** Pipeline::DealsController#show Pipeline::EmailTemplatesController#show SubscribeButtonController#dropdown_for_deal ... AuthorizationRulesController#graph AuthorizationRulesController#change
and it can compare it to your Rails routes.
Finding any routes you have which are never hit.
The gem works by loading the routes into memory and comparing thme with the downloaded data.
Running this on old production apps always seems to find some long forgotten routes.
Stats Instrumentation
- Actions
- Background Events
- Mailers
- Views
- Translations
- One Off Trackers
- Two Methods
Let's look at Custom Stats
Custom Stats instrumentation is very flexible. We are going to look at a number of techniques to gain insight into what your application is actually doing in production.
We will be looking at (read the list).
Stats Instrumentation: Tools
#shared code for examples
STATSD= Statsd.new('stat.my.us', PORT).tap{|sd| sd.namespace = 'app_name'}
REDIS = Redis::Namespace.new(:app_name, :redis => Redis.new)
Which I wanted to quickly mention.
We use graphite via StatsD
I wanted to give a shout out to Etsy here, as we rely heavily on their tools
They have shared in great detail how they also use metrics to gain insights.
StatsD is also extremely performant and while it can be lossy, we haven't ever run into performance issues while adding many metrics.
Below you see some shared constants that will appear in several of the examples.
Internally we have wrappers around our Redis and StatsD usage to deal with things like app name-spacing, common error handling, configurations, etc.
In the examples I am just using Redis and StatsD directly.
Problem: Unused Actions
Earlier we solved this using 3rd party performance tools, but it is easy to solve with some custom stats.
No NewRelic, No Problem
thanks Jeff Whitmire
class ApplicationController < ActionController::Base
before_filter :track_controller_traffic
around_filter :track_controller_timing
def endpoint_name
"#{params['controller'].gsub('/','.')}.#{params['action']}"
end
def track_controller_traffic
STATSD.increment "traffic.total"
STATSD.increment "traffic.#{endpoint_name}"
end
def track_controller_timing
STATSD.time("timing.#{endpoint_name}") do
yield
end
end
Obviously 3rd party performance monitors give you a lot more details than this, but this level of data can still be very useful
We have a couple of ways we have added tracking on endpoints and timing in Rails. I think the simplest and cleanest example was done by Jeff Whitmire.
The code hear just hooks into ApplicationController
Using a simple before filter to increment each endpoint
and using an around filter to record basic timing information for each endpoint.
Comparing your routes to traffic can find no longer used actions.
Problem: Background Events
All events being triggered?
Some jobs will come and go over time. It is pretty easy to remove code that queues a job, while leaving around the job code and related methods.
Background Events
# Example for Resque background jobs
def before_perform(*args)
STATSD.increment "resque.processed.#{get_event_name}"
end
def after_perform(*args)
STATSD.increment "resque.completed.#{get_event_name}"
endWith a bit more work you can record execution time around jobs or success/failures on completion.
This is a simple example assuming hooking into Resque
but is pretty similar for all queueing frameworks.
Problem: Mailers
Are you still sending all your mailers?
Stating every mailer as it is sent lets you know when a mailer is no longer needed.
Alternatively it lets you know your most popular mailers which might be worth spending more time improving.
Mailers
# Example for ActionMailer
class BaseMailer < ActionMailer::Base
def initialize(method_name=nil, *parameters)
STATSD.increment "mailers.base_mailer.#{method_name}" if method_name
#...
super(method_name, *parameters)
end
endLike all the other stats you can check graphite to see if a mailer is out of use before working on the code.
We were able to remove a number of mailers like this opposed to spending the time fixing them when upgrading Rails.
Problem: Views
which views are ever rendered: partials, templates, layouts, for each format?
Templates inside layouts, with partials inside partials... Oh My.
Often a new view gets AB tested and the old one isn't removed.
Devs aren't sure if the partial is used anywhere else. So they copy it and make a new one opposed to changing the shared partial.
Views also bloat out your helpers over time leaving many view specific helpers spread through out the code.
Views Rendered
subscriptions =
render_partial.action_view|render_template.action_view
ActiveSupport::Notifications.subscribe /subscriptions/ do |name, start, finish, id, payload|
RenderTracker.track_template(name, start, finish, id, payload) unless name.include?('!')
end
class RenderTracker
def self.track_template(name, start, finish, id, payload)
if file = payload[:identifier]
STATSD.increment "views.#{file}"
end
if layout = payload[:layout]
Rails.logger.info "[RenderTracker] layout: #{layout}"
end
end
endIn this example we subscribe to
render_partial.action_view and
render_template.action_view
This shows how you can either stat or log via the tracking method.
When working on a view file you can now check what kind traffic volume the change will effect.
Or if the view file you were about to refactor, upgrade, and fix is out of use.
Views Rendered (with Flatfoot)
We made a gem for Rails 3 and up to help: Flatfoot
FLATFOOT = Flatfoot::Tracker.new(REDIS)
ActiveSupport::Notifications.subscribe /render_partial.action_view|render_template.action_view/ do |name, start, finish, id, payload|
FLATFOOT.track_views(name, start, finish, id, payload) unless name.include?('!')
end
FLATFOOT.used_views
=> ["app/views/home/index.html.erb",...
FLATFOOT.unused_views
=> ["app/views/something/_old_partial.html.erb",...So we made a gem called Flatfoot to quickly hook it up into Rails apps.
You can see flatfoot still uses notifications subscriptions and stores view data in a redis set.
It provides some helpers to output unused views by comparing the view renderings with the files on disk.
Making it super simple to dig into view layer cleanup.
Often the biggest wins when removing view files are associated helpers, Javascript, and CSS.
ActiveSupport::Notifications Oddity
###
# Annoyingly while you get full path for templates
# templates with file extensions
# layouts without
# http://edgeguides.rubyonrails.org/active_support_instrumentation.html#render_partial-action_view
###
if layout_file = payload[:layout]
unless logged_views.include?(layout_file)
logged_views << layout_file
store.sadd(tracker_key, layout_file)
end
endActiveSupport violated the principle of least surprise I felt as I was working on this.
Template files in the notifications include the full pathname and file extensions.
For layout files it does not.
It tripped me up a bit so I figured I would mention it. Perhaps someone here can later tell me why.
Flatfoot has some methods to help track layouts without extensions.
Problem: Translations Usage
How many translation keys are you loading in memory & never using?
Over time, it is hard to know which translations are still in use.
Often when changing features and removing old code translations are left behind.
Translation keys end up causing a sizable memory bloat for production rails processes.
As apps load all translations and keep them available in memory.
Translations Usage
We made a gem for that @the_chrismo (Chris Morris) built: Humperdink
class KeyTracker
def initialize(REDIS, key)
redis_set = Humperdink::RedisDirtySet.new(:redis => redis, :key => key, :max_dirty_items => 9)
@tracker = Humperdink::Tracker.new(redis_set, :enabled => true)
end
def on_translate(locale, key, options = {})
begin
if @tracker.tracker_enabled
requested_key = normalize_requested_key(key, options)
@tracker.track(requested_key)
end
rescue => e
@tracker.shutdown(e)
end
end
...The code to set this up is too large to fully display here
but it makes it easy to find unused keys and is optimized for performance.
Check out the gem for more details on how to track translations, but this slide shows a bit of the basics.
Problem: Complex Code Paths
Reading the code, unsure where / if it is called?
Also, frequently in scary dark corners of models, helpers, and libs folders
it is hard to be sure if something is entirely out of use.
For that, one off trackers can be useful.
Tracking format specific endpoints, conditional paths, the ever growing case statement
Really to quickly see the frequency of use of any piece of code.
One Off Trackers
# Example Tracking a code path
class HomeController < ApplicationController
def show
if request.xhr?
#some weird logic
STATSD.increment "deprecated.home_controller.show.xhr"
end
respond_to do |format|
STATSD.increment "deprecated.home.show.#{format}"
format.html { #... }
format.json { #... }
format.mobile { #... }
end
end
endProblem: Two Methods
Which is best, which to keep?
shout out to @ubermajestix (Tyler
Montgomery) for showing me the next trick
Shout out to Tyler Montgomery, who checked this great idea into our git one day.
One off trackers, aren't only useful for finding unused code. It can be a great way to launch performance enhancements.
If you currently have two existing solutions and are decided while refactoring which to use, you can take the guess work out by measure real world usage.
Prod Performance Checks
def example_html_stripping_method
strip_method = rand(2)&1 == 0 ? 'nokogiri' : 'strip_tags'
desc = STATSD.time("application_helper.example_html_stripping_method.#{strip_method}") do
if strip_method == 'strip_tags'
strip_tags(desc_raw).gsub(/^\s+/,'').gsub(/\s+$/,'')
else
Nokogiri::HTML.parse(desc_raw).text.strip
end
end
#...
endLogs

Your application logs are a gold mine of information just waiting to help you out.
When you have multiple applications and you are trying to refactor or remove old endpoints knowing, which clients and versions are using the application can be critical.
Again if you don't have NR or 3rd party performance tools. You can get great rollups of performance for controllers and actions with Kibana, Splunk, or other log querying tools.
Logs
- Logs need to be searchable, real time is best. (ElasticSearch/Kibana, Splunk, Hadoop)
- If you have multiple apps that communicate they should be in the same system.
- All your logs should be in one place (cron, Nginx access/error, background jobs, rails logs)
- Try to standardize log format: important keys / variables across systems
You need a near real time log query tool.
Try to get all your apps logging to the same query tool.
Apps with multiple with logs like nginx, cron, app, and background jobs like wise need to all be sent to the same tool.
You can implement render_tracking, translation_key tracking, and most of the other mentioned systems just by logging data in query-able formats to your logs and crafting the correct queries.
Logs can go deep when you are digging into specific problems like debugging exceptions or finding the last few callers while deprecating endpoints.
Log Queries
# most common format (HTML, JSON) for controller/action
source="*app/*" status=200 |
top format by controller action
# endpoints with more 406 Not acceptable than 200s
source="*app/*" |
stats count(eval(status=406)) as UNAUTH,
count(eval(status=200)) as SUCC
by controller action | where UNAUTH > SUCC
# endpoints with more redirects than 200s
source="*app/*" |
stats count(eval(status=301 OR status=302)) as REDIRECT,
count(eval(status=200)) as SUCC
by controller action |
where REDIRECT > SUCC
# find all requests by a given user
source="*app/*" user_id=XXX
Most common format per action controller pair
Endpoints with more 406 Not acceptable than status 200 success, this often means old clients which are no longer valid are never successfully getting to an endpoint. Perhaps it can be removed
Which endpoint redirects more than returns 200
View all requests by a given user
I just wanted to share a few examples of questions you can answer with your logs.
Logs: Deprecation with caller trace
clean_trace = Rails.backtrace_cleaner.clean(backtrace).join(',')
Rails.logger.info "deprecated=true trace: #{clean_trace}"Tracking that down can be complicated. Detailed logs can help.
You can log the caller inside a method to figure out the call path that reached there.
These deprecation log lines will let you also discover the initial entry point and parameters into your application, if you log request_id, which I will mention shortly.
this idea was introduced into our codebase by Sam Livingston-Gray
def deprecation_trace(backtrace = caller)
log_backtrace(backtrace)
stat_name = stat_name_line(backtrace.first)
STATSD.increment stat_name
end
def log_backtrace(backtrace)
#...
end
TRACE_SUBS = [
[ File.expand_path(Rails.root.to_s) , ''],
[ /:in `(.*)'/, '#\1' ],
[ '.rb' , '' ],
[ /:\d+/ , '' ],
]
def stat_name_line(trace_line)
t_line = TRACE_SUBS.inject(trace_line){ |ln, gsubs|
ln.gsub(*gsubs) }
components = t_line.split(/\W+/).reject(&:blank?).map(&:underscore)
components = %w[ deprecated ] + components
components.join('.')
endYou end up with a really useful deprecation_trace helper method you can use while investigating code to remove.
This code is a bit to complicated to fit on the slide but it basically extracts the class and method name to build a well formatted deprecation namespace.
Making it easy to find code from the stat name.
Logs: Better with Imprint
Make your logs better with Imprint
- Request tracing in logs:
All Rails.logger calls during a request tagged with a trace_id - Exceptions include trace_id so you can fetch all logs related to a request that caused an exception
- Background Jobs failures include the trace_id to find the request that queued the job
- Cross app tracing, have client gems pass a header, and back end APIs will include the same trace_id as the initial front end request
Logs can be particularly useful for this level of information, Imprint helps make your logs easy to trace across apps, jobs, and exceptions.
Imprint builds on ideas from Twitter. Twitter created ZipKin, but most of the tooling is in the Scala world. REcent versions of Rails also provided a request_id which IMPRINT can use.
Imprint makes it easy to capture a request trace and help propagate it through multiple systems. The gem helps simplify the process to integrate it into your tools.
We use imprint in our base internal api-client. This means all inter-app service calls will pass the current requests trace_id as a header to the server. The receiving api service then uses imprint to set the existing trace_id for its logging.
By logging request_id's, and placing that ID in the header, you get a powerful debugging tool.
all your exceptions should now be able to link you back to the original logs related to the request. Similarly failed background jobs, logs can be found, and even traced to the initial request that queued the background job.
Production Code Coverage
Stats takes effort to setup ahead of time and then time to collect and analyze the data.
It seemed like a pattern could be abstracted, which would be more generally useful.
Really I wanted to know how often a given line of code was being run in production.
Ruby VM tooling isn't quite there to let us do this, but it keeps getting better.
while Ruby's StdLib Coverage make this easy to do for tests, it has some bugs that prevent it being used for production.
Ruby 2.1 introduced a sampling profiler, which I am investigating for real time code coverage without larger performance impacts.
Although being on Ruby 2.1 would limit the usefulness for large old monoRail apps.
To get support in Ruby 1.9 I built a solution with set_trace_func
Production Code Coverage: Coverband
- Based on `set_trace_func`
- It would be better to be based on `Coverage` but there is a bug in Ruby
- (Looking for C help, so I can try to patch Ruby, anyone got those skills?)
- Performance hit reduced by sampling
- github.com/danmayer/coverband
To deal with that I allow for request sampling.
We are using it in production on large Rails apps with a low sample rate and collecting some pretty good data.
Unfortunately, the performance hit is pretty large for big applications.
I am running this on Monorail size apps with about 1% of requests being sampled. While I can run 60-90% of requests small Sinatra apps without noticing much of a performance impact.
Unfortunately the Std Lib Coverage bug mentioned was causing segfaults in Ruby 1.9 and 2.0. While tht was fix and it doesn't segfault in 2.1 it still doesn't work correctly when sampling, only reporting data for a file once, ignoring usage after that.
Based on Terance's talk earloer at the conference I am preparing a good and reproducable bug report to submit to ruby-core.
Thanks for inspiring me to do more than complain on twitter, Terence.
Also, I am currently in progress with a native c extension which should significantly improve performance. This would allow faster data collection still going back to Ruby 1.9
br/> If anyone has strong C skills and is interested in helping out, I am definitely in need of some help in this area.
Production Code Coverage: Coverband
Example Output: churn-site coverage
Production Code Coverage: Coverband
baseline = Coverband.parse_baseline
Coverband.configure do |config|
config.root = Dir.pwd
config.redis = REDIS
config.coverage_baseline = baseline
config.root_paths = ['/app/']
config.ignore = ['vendor']
config.startup_delay = Rails.env.production? ? 15 : 1
config.percentage = Rails.env.production? ? 10.0 : 95.0
config.stats = STATSD
config.verbose = Rails.env.production? ? false : true
config.logger = Rails.logger
endTo configure coverband you can either put this config block where necessary of place it in `config/coverband.rb` which it gets picked up when you call Coverband.configure.
`Coverband.parse_baseline` tells Coverband where to find a baseline recording of code coverage just from loading the application. A lot of Ruby code is run just loading the Rails app, and that isn't capture during the request cycle. So we can just record that once and merge it in with live coverage data.
Setting it up, you can see I provide different settings for development and production. It makes it easier to test and verify in development with a large sample rate.
A couple settings to note, `config.startup_delay` Rails defines a lot of methods dynamically on the first few requests so they are ignored because they can run much slower with Coverband.
percentage is the number of requests that we will sample and record with coverband.
ignore lets you not record section of code you wish to skip. Skipping heavy non app code like vendor or lib can also help to reduce the performance impact.
Production Code Coverage: Coverband
#configure rake
require 'coverband'
Coverband.configure
require 'coverband/tasks'
#setup middleware in `config.ru`
require File.dirname(__FILE__) + '/config/environment'
require 'coverband'
Coverband.configure
use Coverband::Middleware
run ActionController::Dispatcher.newIn this example I am setting up the middleware as early as possible in the `config.ru`. You can also, just set it up in the standard Rails middleware stack.
Production Code Coverage: Coverband
config.verbose = 'debug'
coverband file usage:
["./app/models/deal_modules.rb", 9],
...
["./app/models/deal.rb", 20606],
["./app/helpers/application_helper.rb", 43150]]
file:
./app/helpers/application_helper.rb =>
[[448, 1], [202, 1],
...
[516, 38577]]If you enable verbose mode in the config, at the end of each request it outputs how often a file was accessed.
If you set verbose mode to 'debug' it will further break down the number of times an individual line on a file was called.
In the example output of the slide you can see application helper was hit 43K times during this request. While like 516 of that file was hit 38K times.
That doesn't always mean there is a problem, but it might be worth investigating what is going on there.
Gems
- New Relic Helpers:
livingsocial/newrelic_route_check - View Render Tracking:
livingsocial/flatfoot - Translation Tracking:
livingsocial/humperdink - Log Helpers:
livingsocial/imprint - Production Code Coverage:
danmayer/coverband
These are all open source released by various LivingSocial engineers.
Other Useful Gems
- many things from Aman Gupta (@tmm1)
- Ruby Profilers
- Perftools.rb and related rack preftools from @bhb (Ruby < 2.1)
- Stackprof Modern Replacement for Perftools.rb (Ruby >= 2.1)
- rbtrace (like strace for Ruby)
- rblineprof
- Rack Warmup to avoid performance hits on initial requests
- A history of Ruby's GC
- gctools out of band GC tools optimized for Ruby 2.1
- Sam Rawlins (@srawlins) awesome GC work.
- AllocationStats GC tooling
- rack-allocation_stats making GC tooling even more accessible
- Ruby 2.1 Awesomeness: Pro Object Allocation Tracing (mtnwest ruby talk)
- MethodProfiler from Change.org
- busted find method cache invalidation by Simeon Willbanks
- Ruby 2.0 and Systemtap
So I wanted to point out some other gems and tools that can either help you understand what is going on with your system or with the performance of the code as it runs. Some of these tools can be used in production while others are a probably best in development only until the tooling gets better.
Anything by by Aman Gupta is generally awesome. Not only has he released amazing gems and tools. He is now on the frontline improving the Ruby VM to help it provide valuable runtime data back to clients.
Sam Rawlins has been doing amazing work related to GC tools to help you understand what is going on on systems. I recommend his MtnWestRuby talk
change.org has related a interesting MethodProfiler tool.
Simeon Willbanks has a interesting tool that will collect method cache invalidations for Ruby 2.1
A lot of great work is going on to help give us better insights into what is happening with our code on production.
Thanks
- Dan Mayer
- LivingSocial
(We're hiring)
Thanks for listening, hope you found some of this useful for your applications.