
Availability, Outages, Reliability, and SLAs
TODO:
- Grammarly
Availability, Outages, Reliability, and SLAs
As companies mature, eventually downtime moves from speculative loss of revenue or customer growth, to directly impacting revenue and decreasing active customer trust. The tradeoffs of move fast and find market fit changes when a business shifts to driving revenue from a working business plan. This shifts the dynamics and companies working with processes and models that worked during early startup growth often struggle with the shift, understanding where new products and features can still learn and change fast, while more established critical systems require different approaches. In this post, I want to take a look at some of the different and related concerns around building reliable services.
Outages and Uptime
When talking about reliability folks can mean different things… Measuring uptime in terms of total site availability. When talking about outages and uptime, folks generally mean the entire experience is available and aren’t concenred with invididual request level success. If the site is generally a bit slow and functions within normal bonds it is considered to be available and not suffering from an outage, even if the p99 is not looking good.
Planned Vs Unplanned Downtime
In all the discussion below we are focused on unplanned downtime and the risk assement to a business and service. Planned downtime should be part of the plan and help with risk mitagation. It is built in and schedulable for nearly all cloud services, because one way to mitagate risk is controlling for planned downtime during the lowest impact to users and the business. Further discussion of planned downtime is out of scope of this post.
Why not just build for High Availability and Five Nines from the Start?
A quick note since some folks try to push for massive scale or availability far before it is needed. I recommend not not Five nines: chasing the dream?, from the start. It doesn’t really work and it isn’t worth it, and most companies have learned that it isn’t worth the opportunity cost.
- Google doesn’t do it
- Amazon Doesn’t do it
- If you build off cloud services, and if you build off their clouds you likely really aren’t either (we will cover this more later)
I have worked at a number of companies at various sizes and stages of growth, and seen companies grow to global scale while still never reaching high availability at a multi-region level. This isn’t to say you may not want to design for that level of resilience depending on your business, but you might be surpised at the number of companies that have gone public before needed to tackle that problem.
users typically don’t notice the difference between high reliability and extreme reliability in a service, because the user experience is dominated by less reliable components like the cellular network or the device they are working with. Put simply, a user on a 99% reliable smartphone cannot tell the difference between 99.99% and 99.999% service reliability! –Google SRE Book
Difference between Outages and Normal Operations
One thing to note is most of the time core services don’t have total outages anymore, but they do happen and there are ways to prepare for them… A more common day to day impact on users of your systems is operational efficiency in terms of both success rate and performance.
Total Infrastructure Outages
Much of this is outside your control and you are dependent on your provides, but there are some patterns with providers or across multiple providers to mitgate incrustructure issues. The ability to change these more often lies with platform and infrastructure teams, but often comes with high cost, increased complexity, and little value outside of the risk mitigation. Having high availability around redundant CDN providers with DNS failovers as an example is an expensive solution to a problem that seems to occur every few years for CDN providers.
- AWS Cloudfront
- AWS Region
- AWS S3
- Fastly outage
This category, is where you might want to be thinking more in terms of Time-based availability opposed to Aggregate availability These are often rare occurances where massive systems fail and the only way to prepare for them is building multiple redundant systems ahead of time.
Total Application Services Outages
These are system level issues that cause outages that are under your application, platform, and infrastructure engineers control. A number of stragies can be applied both at platform and application level to reduce risk
- configuration change mistake
- application code logic mistake
- data store failure (DB migration mistake)
- system overload
- bad host issues
- thundering herd
This category, is where you might want to be thinking more in terms of Time-based availability, as these types of outages aren’t just expected built in failure rates that all services should be built to handle as part of normal opperations, these are trigged by faulty changes, unexpected load, out of expectation infrastructure issues.
Total 3rd Party Integration Outages
You might have some 3rd parties that are in portions of your critical path… Similar to infrastructure outages you are slightly dependant on your partners, but unlike infrastructure most mitigations can be handled by Eng or Platform teams opposed to infrastructure teams. For example, if you offer multiple logins you should ensure a single auth provider can’t take down your login page or consume so many web workers while timing out that it is impossible to process other login sources successfully.
- braintree
- paypay
- stripe
- FB Auth
- Google Auth
- Apple ID
- authzero
- onelogin
Daily Service Quality
This is the impact of day to day expected success rates, latency, and failures that should be expected during normal operations. The effect of these issues is somehting your application teams have the ability to impact and control the outcomes of. Note: that all your third parties also have spikes in latency, error rates, and can for partial outages be mitigated by eng and platform teams.
Micro Service SLAs
The issue with SLAs is that folks often want to aim for extremly high SLAs like “five nines” 99.999% uptime… Companies also want high fully independent teams running and managing microservices… Let’s take a look at how this plays out. Every time you add another service dependency you reduce the theoritical maximum SLA you could provide.
Basic Single Application Stack Request Flow
In this example I am using Sankey diagrams to attempt to visualize the flow of a request from clients through an example infrastructure stack.
- A single request (like a request for an html page or single API request)
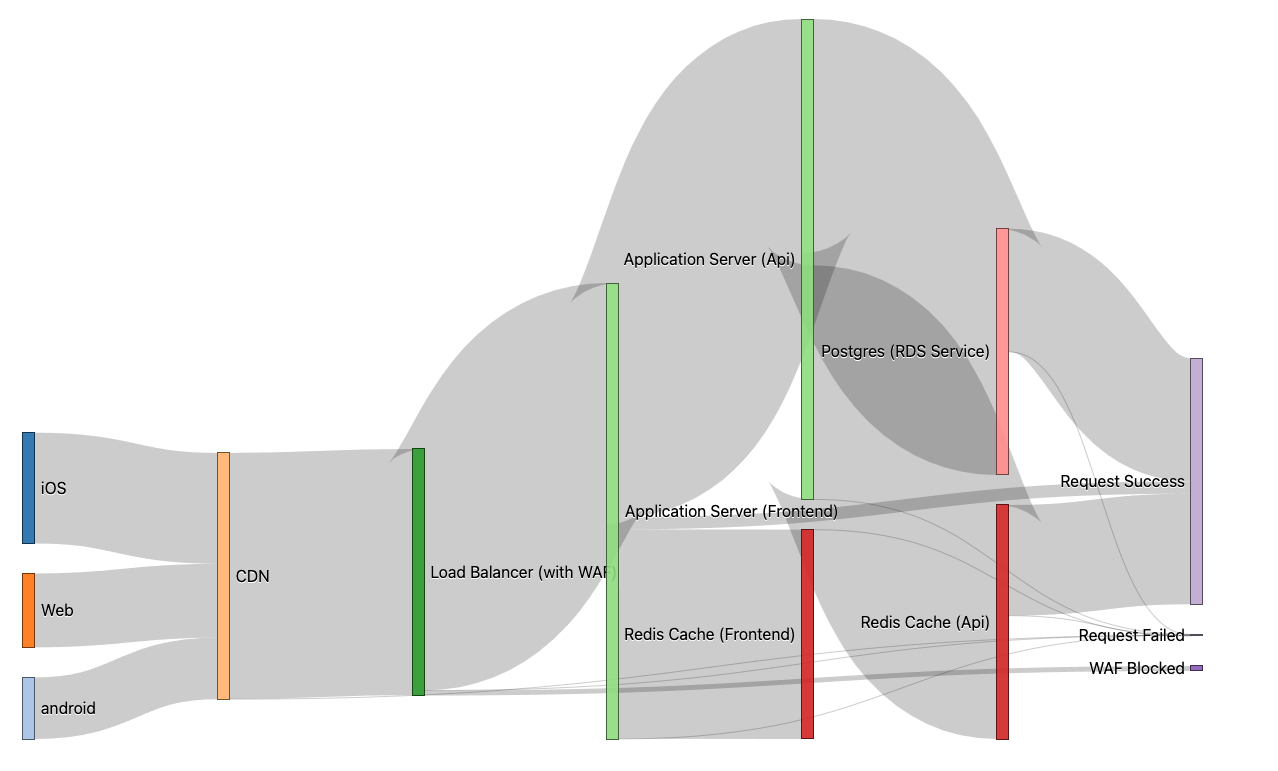
Micro Service Requests
An Example of a Microservice Architecture.
- Includes: a web front-end, API service, and common supporting services (DB and Redis Cache)
Microservice SLAs
micro
> (0.999) * 100 => 99.9 > (0.999 * 0.999) * 100 => 99.8001 > (0.999 * 0.999 * 0.999) * 100 => 99.7002999 > (0.999 * 0.999 * 0.999 * 0.999) * 100 => 99.6005996001 > (0.999 * 0.999 * 0.999 * 0.999 * 0.999) * 100 => 99.5009990004999 > (0.999 * 0.999 * 0.999 * 0.999 * 0.999 * 0.999) * 100 => 99.4014980014994
AWS SLAs
Let’s look at this from the perspective of a typical AWS applications, assuming a single app stack (no micro services), a pretty standard setup with app code of 99.9% still leaves a total SLA max of %99.6
cloudfront ALB ECS YOUR APP Elasticache RDS (Postgres) (0.999 * 0.9999 * 0.9999 * 0.999 * 0.999 * 0.9995) * 100 => 99.63052065660449
You can see as you stack AWS services, regardless of your application stability, request success percentage decreases…
| Service | SLA | % Success Math | Request % Success |
|---|---|---|---|
| cloudfront | 99.9 | 0.999 | 99.9% |
| ALB | 99.99 | 0.999 * 0.9999 | 99.89% |
| ECS | 99.99 | 0.999 * 0.9999 * 0.9999 | 99.88% |
| Custom App | 99.9 | 0.999 * 0.9999 * 0.9999 * 0.999 | 99.78% |
| Elasticache | 99.9 | 0.999 * 0.9999 * 0.9999 * 0.999 * 0.999 | 99.68% |
| RDS (Postgres) | 99.95 | 0.999 * 0.9999 * 0.9999 * 0.999 * 0.999 * 0.9995 | 99.63% |
Impacts of the internet
Now let’s consider that even if one has achived all of this, are your customers actually receiving “five nines” of service?
If we consider their provider ISP (assuming home internet connections via ISPs), local wifi setup, or even worse a mobile connection… You can already drop expectations to at least %99.9, really you are trying to make your service appear as stable as their internet, with as many network failures as the customer has to endure with any other serivce.
If failures are being measured from the end-user perspective and it is possible to drive the error rate for the service below the background error rate, those errors will fall within the noise for a given user’s Internet connection. While there are significant differences between ISPs and protocols (e.g., TCP versus UDP, IPv4 versus IPv6), we’ve measured the typical background error rate for ISPs as falling between 0.01% and 1%. -- Embracing Risk, Site Reliability Engineering
WHAT ABOUT COST ^^ Google covers as well