
Micro-Service Request Depth Availability
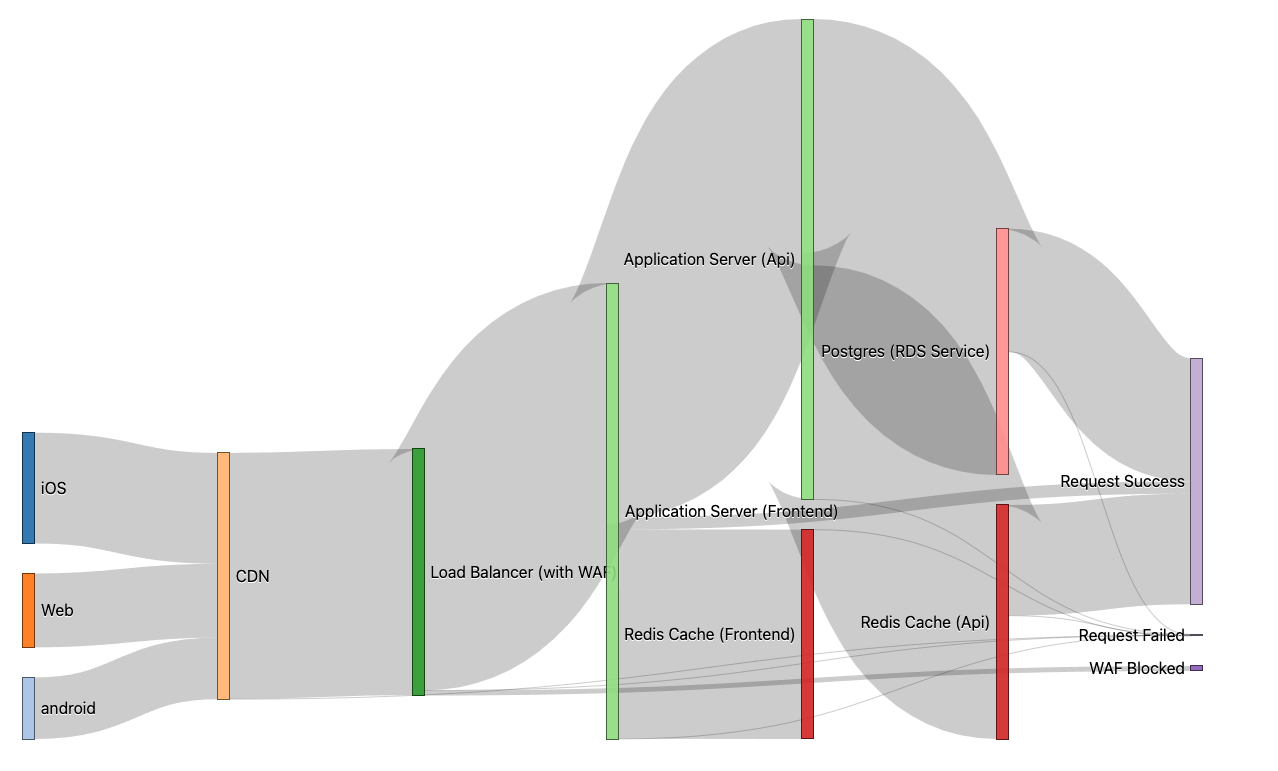
Micro-Service Request Depth Availability
In systems that use micro-services, often the growth and interaction of the services grow organically over time. While it is enabling teams to move quickly and integrate whatever they need it leads to some known bad patterns in terms of micro-service interactions that have serious impacts on availability. This post explains two of micro-service integration anti-patterns calling them “The Mesh” (I prefer Distributed Monolith) and “Services in Depth”. In both, the issue is a single request into your system can fan out to many individual services both in breadth and depth. Most micro-service systems I have seen have a mix of both fan-outs in-breadth and deep lines of service depths in some cases.
Understand the Implecations of Deep Service Call Depth
Let’s consider service depth, as the simpler version of the problem to reason about. When a team is investing going micro-services some breath and depth calls are to be expected but understanding what it means and how to consider the impacts in the designing of the system. Below we will consider that each application has an aggregate request availability of 99.9%.
What does the request success rate look like for a request with 6 micro-service call depth?
> (0.999) * 100 => 99.9 > (0.999 * 0.999) * 100 => 99.8001 > (0.999 * 0.999 * 0.999) * 100 => 99.7002999 > (0.999 * 0.999 * 0.999 * 0.999) * 100 => 99.6005996001 > (0.999 * 0.999 * 0.999 * 0.999 * 0.999) * 100 => 99.5009990004999 > (0.999 * 0.999 * 0.999 * 0.999 * 0.999 * 0.999) * 100 => 99.4014980014994
Assuming each service has an aggregate availability of 99.9%, A service call depth of 6 has a request availability of %99.4
This is likely a lot lower than teams expected. Also, often depending on your infrastructure it is a lot easier to stack up to six network calls than you may think. Also, while I am not covering the impact to latency in this post, understand it will have a large and negative impact on latency for a deep request call stack.
Visualizing The Request Failure Rate
A nice way to think about the combined success rate is by thinking of each network hop as having a small opportunity for failure. These failure threads peel off as requests navigate the micro-service call stack. As the complexity of the network communications increases and the call depth deepens, the likelihood of failure increases as well. This would include things like your load balancer, DBs, App servers, and application caches.
Each network hop is an opportunity for failure, in the above showing 7 failure opportunities
Request Depth Failure Trends
Another way to visualize this is just a simple bar chart showing a decline of expected availability as service depth grows.
Micro-Service Request Availability Calculator
The below calculator will let you quickly estimate your theoretical availability based on the estimated SLA across multiple service calls. Consider each part of your infrastructure (CDNs, load balancers, DBs, Caches) as well as the total services involved in a successful response to a request.
Micro-Service Call Depth Availibility Calculator
AWS SLAs
So far we have been talking about micro-services and their availability, we should consider the services often used to host our application code into the cloud. A very popular cloud for hosting service is AWS, which publishes all AWS SLAs. Let’s look at this from the perspective of a typical AWS application, assuming a single app stack (no micro-services), a pretty standard setup, and assuming the app code has a runtime SLA of 99.9%, the combined math leaves a total theoretical max request success expectation of %99.6. If you are building something that needs extremely high reliability, are you able to keep availability promises?]
You can see as you stack AWS services, regardless of your application stability, request success percentage decreases…
| Service | SLA | % Success Math | Request % Success |
|---|---|---|---|
| cloudfront | 99.9 | 0.999 | 99.9% |
| ALB | 99.99 | 0.999 * 0.9999 | 99.89% |
| ECS | 99.99 | 0.999 * 0.9999 * 0.9999 | 99.88% |
| Custom App | 99.9 | 0.999 * 0.9999 * 0.9999 * 0.999 | 99.78% |
| Elasticache | 99.9 | 0.999 * 0.9999 * 0.9999 * 0.999 * 0.999 | 99.68% |
| RDS (Postgres) | 99.95 | 0.999 * 0.9999 * 0.9999 * 0.999 * 0.999 * 0.9995 | 99.63% |
Mitigations / Considerations
When you realize as the system scales and grows and the number of total microservice dependencies a typical request into your system may have, it is worth thinking about and considering some mitigation strategies. Opposed to pushing towards Five Nines: Chasing The Dream?, embrace failure and resilience, find an acceptable and achievable level of availability for your service. Then invest in mitigation techniques and strategies to deliver a reliable client experience on unreliable internet. A few examples of mitigations are listed below.
-
Client Side Retries: A good reason to have client-side retries and avoid implementing retries at all levels of the infrastructure (some other special cases may make sense to avoid full round trips). See Google’s SRE book, sections Client-Side Throttling and Deciding to Retry from the Handling Overload chapter.
-
Be Wary of Circular Graphs: Detect circular graphs, even if this can technically be supported in your infrastructure, it may be best to avoid as a way to force folks to think through more robust and scalable solutions.
- Avoid Duplicate Service Calls: This happens when you might have a very common piece of data that a service calls, before you know it all your micro-services call this in high demand service. You might have an initial request fan out to 3 micro-services that all call this common data service under the hood. This often happens for something like user data.
- Consider common data and look at data forwarding, which can early in the request processing add metadata that is sent to all upstream requests. Avoiding all upstream requests from making individual network requests for the data.
- Agree on Constraints: Consider alerting on requests that exceed an agreed maximum service call depth or circular call graphs.
Conclusion
There are a lot of benefits of microservices, but I feel like the expectations around reliability and latency are often overlooked when folks move from a larger shared codebase and adopt microservices. The companies are looking for faster deployments and teams that move independently and do not fully grasp that they slowly have turned every method call or DB join into a remote network request with all the failures and performance characteristics that come with it.